x 按十六进制格式显示变量。 d 按十进制格式显示变量。 u 按十进制格式显示无符号整型。 o 按八进制格式显示变量。 t 按二进制格式显示变量。 a 按十六进制格式显示变量。 i 指令地址格式 c 按字符格式显示变量。 f 按浮点数格式显示变量。
地址单元长度 u 取值
1 2 3 4
b表示单字节, h表示双字节, w表示四字节, g表示八字节
example
1 2
x/50xw 0x40451400
50是数量,x是16进制,w是四字节
Examining Memory
You can use the command x (for “examine”) to examine memory in any of several formats, independently of your program’s data types.
1 2 3
x/nfu addr x addr x
Use the x command to examine memory.
n, f, and u are all optional parameters that specify how much memory to display and how to format it; addr is an expression giving the address where you want to start displaying memory. If you use defaults for nfu, you need not type the slash ‘/’. Several commands set convenient defaults for addr.
n, the repeat count
The repeat count is a decimal integer; the default is 1.
It specifies how much memory (counting by units u) to display.
If a negative number is specified, memory is examined backward from addr.
f, the display format
The display format is one of the formats used by print
(‘x’, ‘d’, ‘u’, ‘o’, ‘t’, ‘a’, ‘c’, ‘f’, ‘s’),
‘i’ (for machine instructions) and ‘m’ (for displaying memory tags).
The default is ‘x’ (hexadecimal) initially.
The default changes each time you use either x or print.
u, the unit size
The unit size is any of
1 2 3 4 5 6 7 8 9 10 11
b Bytes.
h Halfwords (two bytes).
w Words (four bytes). This is the initial default.
g Giant words (eight bytes).
Each time you specify a unit size with x, that size becomes the default unit the next time you use x.
For the ‘i’ format, the unit size is ignored and is normally not written.
For the ‘s’ format, the unit size defaults to ‘b’, unless it is explicitly given.
Use x /hs to display 16-bit char strings and x /ws to display 32-bit strings. The next use of x /s will again display 8-bit strings.
Note that the results depend on the programming language of the current compilation unit.
If the language is C, the ‘s’ modifier will use the UTF-16 encoding while ‘w’ will use UTF-32. The encoding is set by the programming language and cannot be altered.
modify memory
In order to set the variable g, use
1
(gdb) set var g=4
GDB allows more implicit conversions in assignments than C; you can freely store an integer value into a pointer variable or vice versa, and you can convert any structure to any other structure that is the same length or shorter.
To store values into arbitrary places in memory, use the ‘{…}’ construct to generate a value of specified type at a specified address (see Expressions). For example, {int}0x83040 refers to memory location 0x83040 as an integer (which implies a certain size and representation in memory), and
1
set {int}0x83040 = 4
stores the value 4 into that memory location.
This should work for any valid pointer, and can be cast to any appropriate data type.
1
set *((int *) 0xbfbb0000) = 20
e.g.
1 2 3 4 5 6 7 8 9 10 11 12
set *(unsigned char *)<memaddr> = <value> ; write 1 byte set *(unsigned short *)<memaddr> = <value> ; write 2 bytes set *(unsigned int *)<memaddr> = <value> ; write 4 bytes set *(unsigned long long *)<memaddr> = <value> ; write 8 bytes or set *(char *)<memaddr> = <value> ; write 1 byte set *(short *)<memaddr> = <value> ; write 2 bytes set *(int *)<memaddr> = <value> ; write 4 bytes set *(long long *)<memaddr> = <value> ; write 8 bytes
int ret; u32 width; u32 bits_per_pixel; structdisplay_timings *timings =NULL;
/* get display node from device tree , pdev->dev.of_node : from father node*/ display_np = of_parse_phandle(pdev->dev.of_node, "display", 0);
/* get common info 通用属性 */ ret = of_property_read_u32(display_np, "bus-width", &width); ret = of_property_read_u32(display_np, "bits-per-pixel", &bits_per_pixel);
/* get timings from device tree */ timings = of_get_display_timings(display_np);
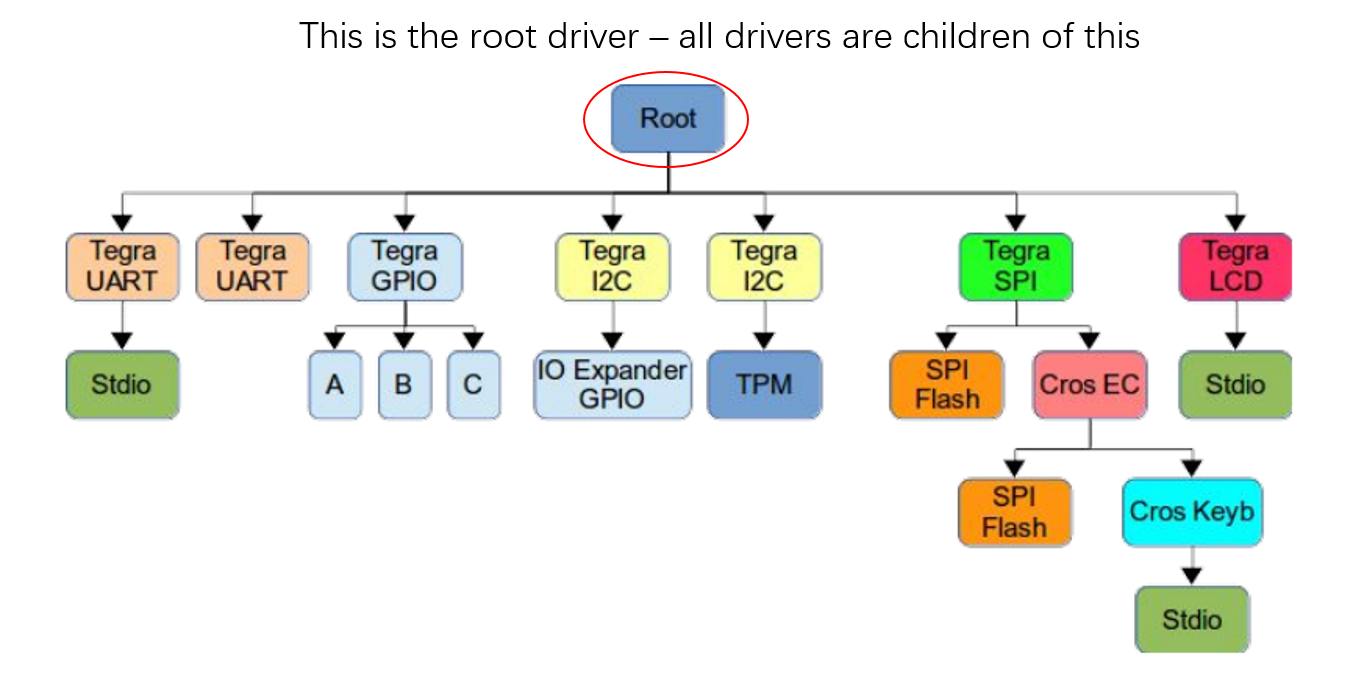
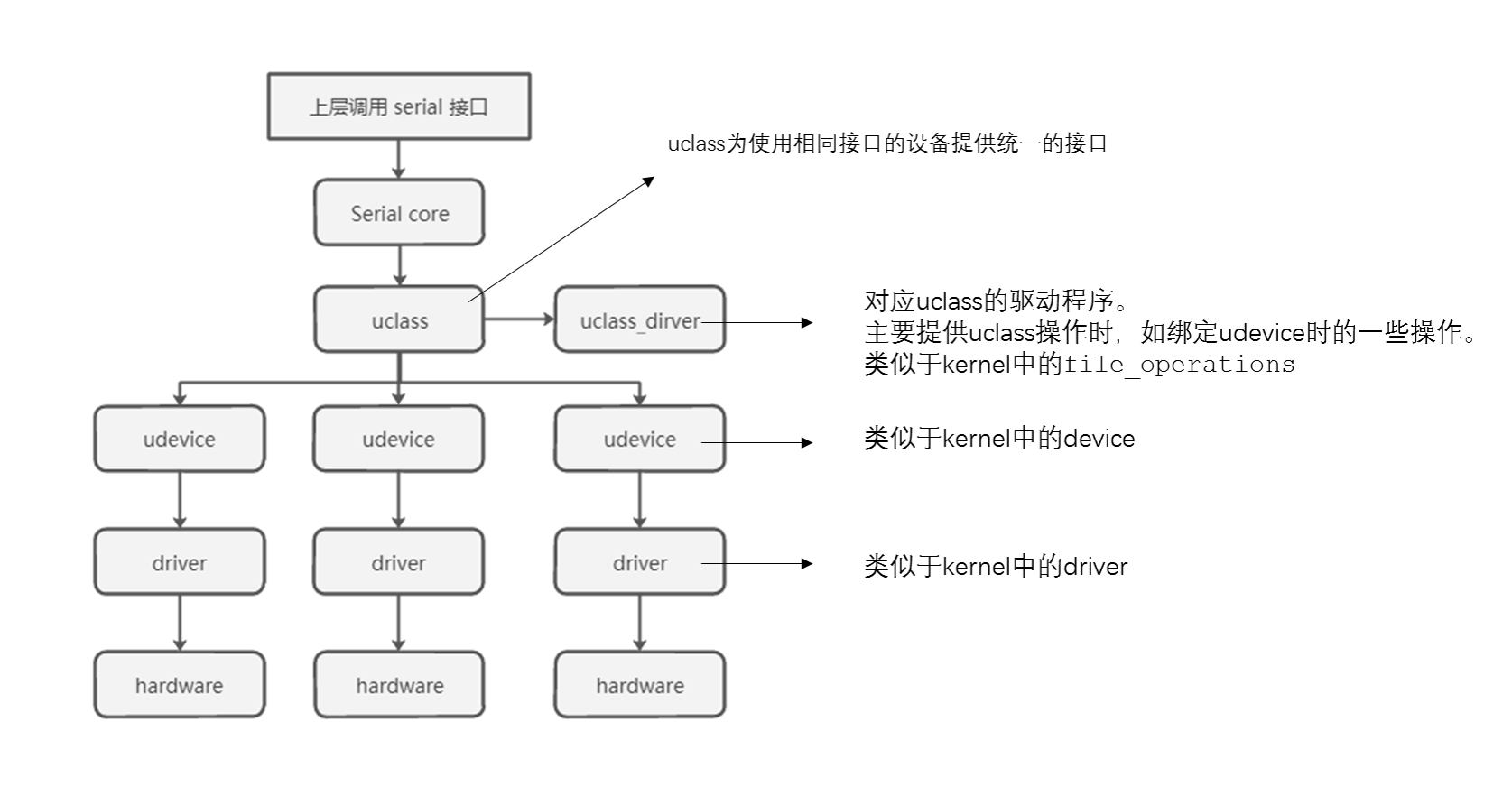
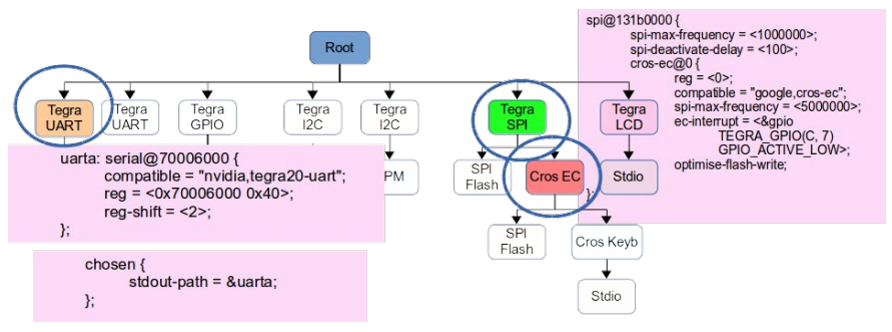
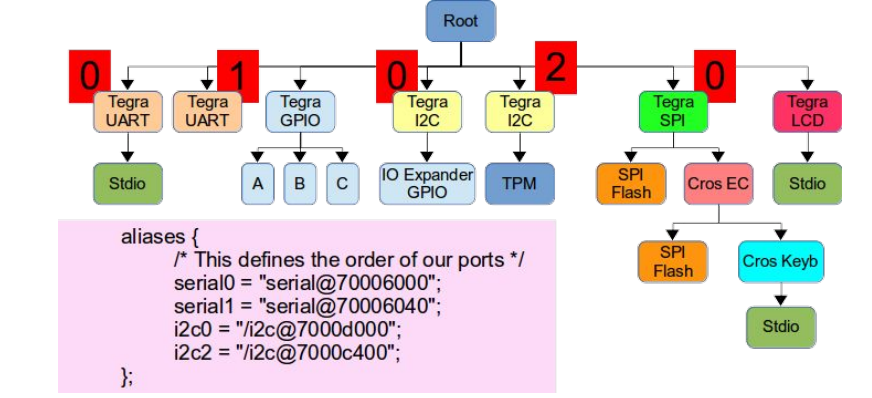
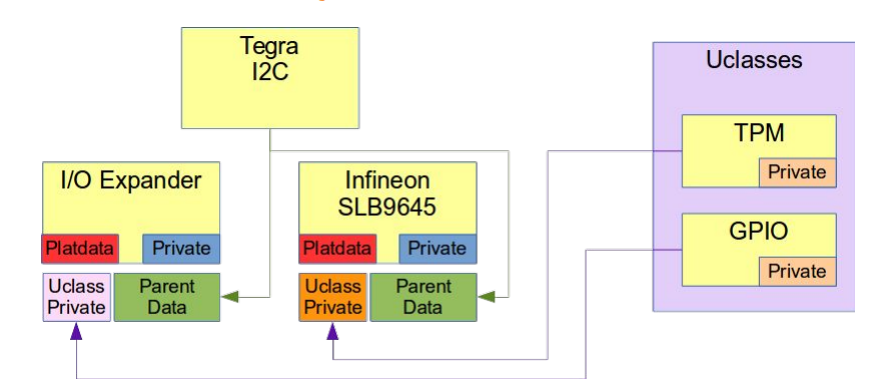
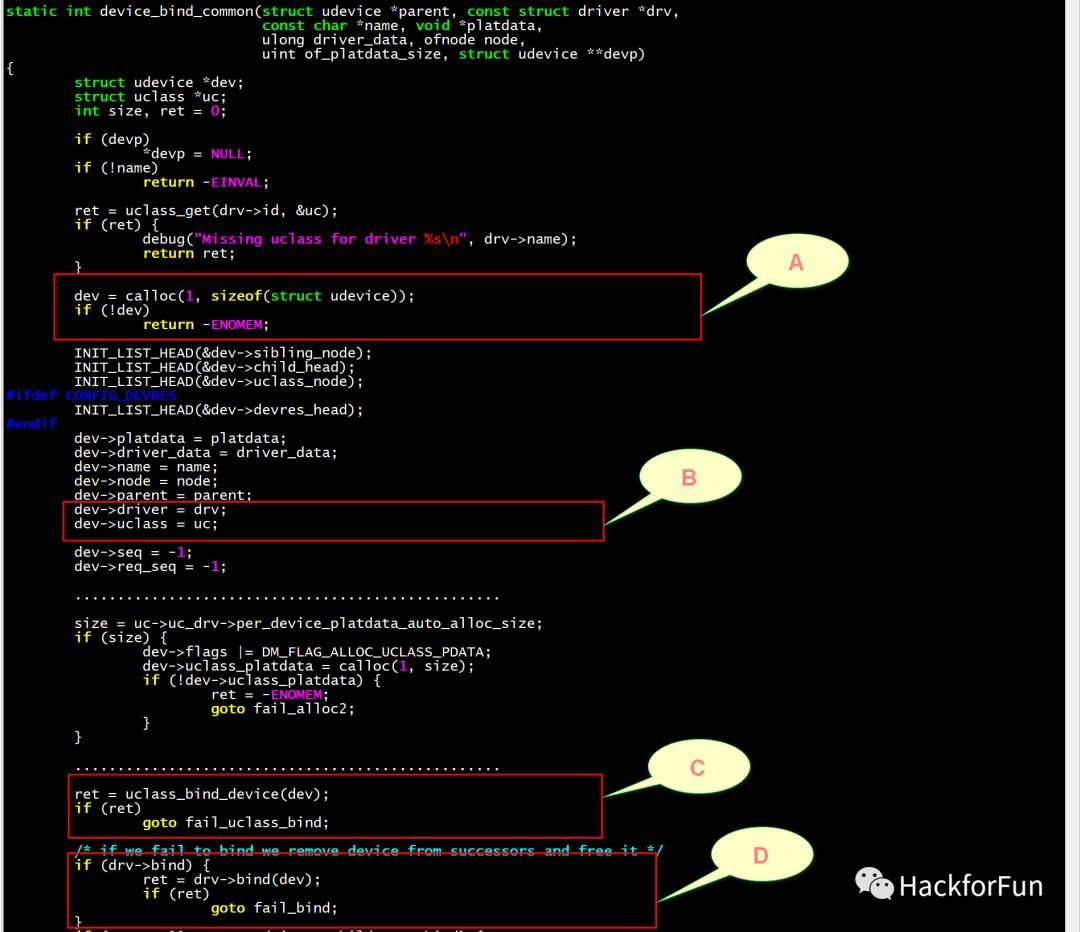
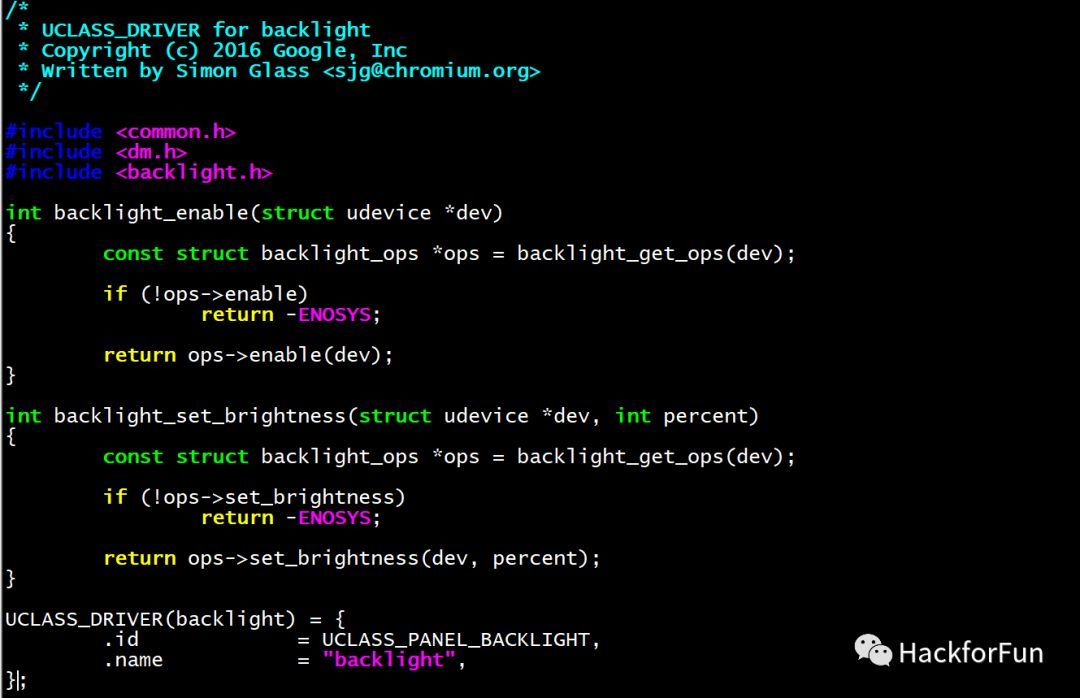
/** * struct udevice - An instance of a driver * * This holds information about a device, which is a driver bound to a * particular port or peripheral (essentially a driver instance). * * A device will come into existence through a 'bind' call, either due to * a U_BOOT_DEVICE() macro (in which case platdata is non-NULL) or a node * in the device tree (in which case of_offset is >= 0). In the latter case * we translate the device tree information into platdata in a function * implemented by the driver ofdata_to_platdata method (called just before the * probe method if the device has a device tree node. * * All three of platdata, priv and uclass_priv can be allocated by the * driver, or you can use the auto_alloc_size members of struct driver and * struct uclass_driver to have driver model do this automatically. * * @driver: The driver used by this device * @name: Name of device, typically the FDT node name * @platdata: Configuration data for this device * @parent_platdata: The parent bus's configuration data for this device * @uclass_platdata: The uclass's configuration data for this device * @node: Reference to device tree node for this device * @driver_data: Driver data word for the entry that matched this device with * its driver * @parent: Parent of this device, or NULL for the top level device * @priv: Private data for this device * @uclass: Pointer to uclass for this device * @uclass_priv: The uclass's private data for this device * @parent_priv: The parent's private data for this device * @uclass_node: Used by uclass to link its devices * @child_head: List of children of this device * @sibling_node: Next device in list of all devices * @flags: Flags for this device DM_FLAG_... * @req_seq: Requested sequence number for this device (-1 = any) * @seq: Allocated sequence number for this device (-1 = none). This is set up * when the device is probed and will be unique within the device's uclass. * @devres_head: List of memory allocations associated with this device. * When CONFIG_DEVRES is enabled, devm_kmalloc() and friends will * add to this list. Memory so-allocated will be freed * automatically when the device is removed / unbound */ structudevice { conststructdriver *driver; constchar *name; void *platdata; void *parent_platdata; void *uclass_platdata; ofnode node; ulong driver_data; structudevice *parent; void *priv; structuclass *uclass; void *uclass_priv; void *parent_priv; structlist_headuclass_node; structlist_headchild_head; structlist_headsibling_node; uint32_t flags; int req_seq; int seq; #ifdef CONFIG_DEVRES structlist_headdevres_head; #endif };
有三种途径生成一个 udevice:
dts 设备节点
UBOOTDEVICE(__name) 宏申明
调用 ‘bind’ API, device_bind_xxx
Device Model Start-up sequence
DM 启动顺序, core/root.c
dm_init_and_scan():
dm_init()
Creates an empty list of devices and uclasses
Binds and probes a root device
dm_scan_platdata()
Scans available platform data looking devices to be created
Platform data may only be used when memory constrains prohibit device tree
dm_scan_fdt()
Scan device tree and bind driver to nodes to create devices
| -> dm_init_and_scan | -> dm_init | -> INIT_LIST_HEAD //创建 root 节点 | -> device_bind_by_name() | -> lists_driver_lookup_name //lists_driver_lookup_name("root_driver"), This function returns a pointer a driver given its name. | -> ll_entry_start //Point to first entry of linker-generated array | -> ll_entry_count //Return the number of elements in linker-generated array | -> for { strcmp } //通过名字来遍历,得到匹配的 driver | -> device_bind_common | -> uclass_get | -> uclass_find //Find uclass by uclass_id | -> list_add_tail //put dev into parent's successor list | -> uclass_bind_device | -> device_probe | -> | -> dm_scan_platdata | -> dm_extended_scan_fdt | -> dm_scan_other
/** * struct uclass - a U-Boot drive class, collecting together similar drivers * * A uclass provides an interface to a particular function, which is * implemented by one or more drivers. Every driver belongs to a uclass even * if it is the only driver in that uclass. An example uclass is GPIO, which * provides the ability to change read inputs, set and clear outputs, etc. * There may be drivers for on-chip SoC GPIO banks, I2C GPIO expanders and * PMIC IO lines, all made available in a unified way through the uclass. * * @priv: Private data for this uclass * @uc_drv: The driver for the uclass itself, not to be confused with a * 'struct driver' * @dev_head: List of devices in this uclass (devices are attached to their * uclass when their bind method is called) * @sibling_node: Next uclass in the linked list of uclasses */ structuclass { void *priv; structuclass_driver *uc_drv; structlist_headdev_head; structlist_headsibling_node; };
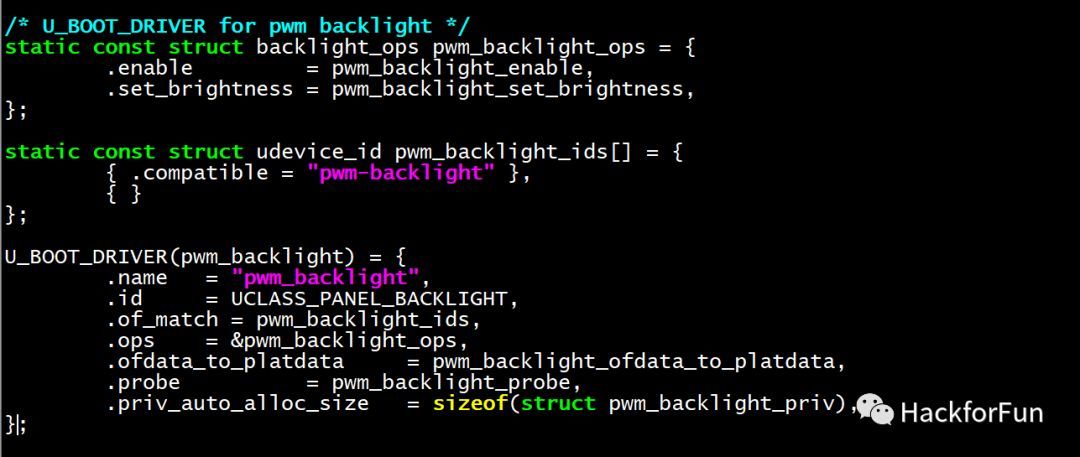
/** * struct driver - A driver for a feature or peripheral * * This holds methods for setting up a new device, and also removing it. * The device needs information to set itself up - this is provided either * by platdata or a device tree node (which we find by looking up * matching compatible strings with of_match). * * Drivers all belong to a uclass, representing a class of devices of the * same type. Common elements of the drivers can be implemented in the uclass, * or the uclass can provide a consistent interface to the drivers within * it. * * @name: Device name * @id: Identifies the uclass we belong to * @of_match: List of compatible strings to match, and any identifying data * for each. * @bind: Called to bind a device to its driver * @probe: Called to probe a device, i.e. activate it * @remove: Called to remove a device, i.e. de-activate it * @unbind: Called to unbind a device from its driver * @ofdata_to_platdata: Called before probe to decode device tree data * @child_post_bind: Called after a new child has been bound * @child_pre_probe: Called before a child device is probed. The device has * memory allocated but it has not yet been probed. * @child_post_remove: Called after a child device is removed. The device * has memory allocated but its device_remove() method has been called. * @priv_auto_alloc_size: If non-zero this is the size of the private data * to be allocated in the device's ->priv pointer. If zero, then the driver * is responsible for allocating any data required. * @platdata_auto_alloc_size: If non-zero this is the size of the * platform data to be allocated in the device's ->platdata pointer. * This is typically only useful for device-tree-aware drivers (those with * an of_match), since drivers which use platdata will have the data * provided in the U_BOOT_DEVICE() instantiation. * @per_child_auto_alloc_size: Each device can hold private data owned by * its parent. If required this will be automatically allocated if this * value is non-zero. * @per_child_platdata_auto_alloc_size: A bus likes to store information about * its children. If non-zero this is the size of this data, to be allocated * in the child's parent_platdata pointer. * @ops: Driver-specific operations. This is typically a list of function * pointers defined by the driver, to implement driver functions required by * the uclass. * @flags: driver flags - see DM_FLAGS_... */ structdriver { char *name; enumuclass_idid; conststructudevice_id *of_match; int (*bind)(struct udevice *dev); int (*probe)(struct udevice *dev); int (*remove)(struct udevice *dev); int (*unbind)(struct udevice *dev); int (*ofdata_to_platdata)(struct udevice *dev); int (*child_post_bind)(struct udevice *dev); int (*child_pre_probe)(struct udevice *dev); int (*child_post_remove)(struct udevice *dev); int priv_auto_alloc_size; int platdata_auto_alloc_size; int per_child_auto_alloc_size; int per_child_platdata_auto_alloc_size; constvoid *ops; /* driver-specific operations */ uint32_t flags; };
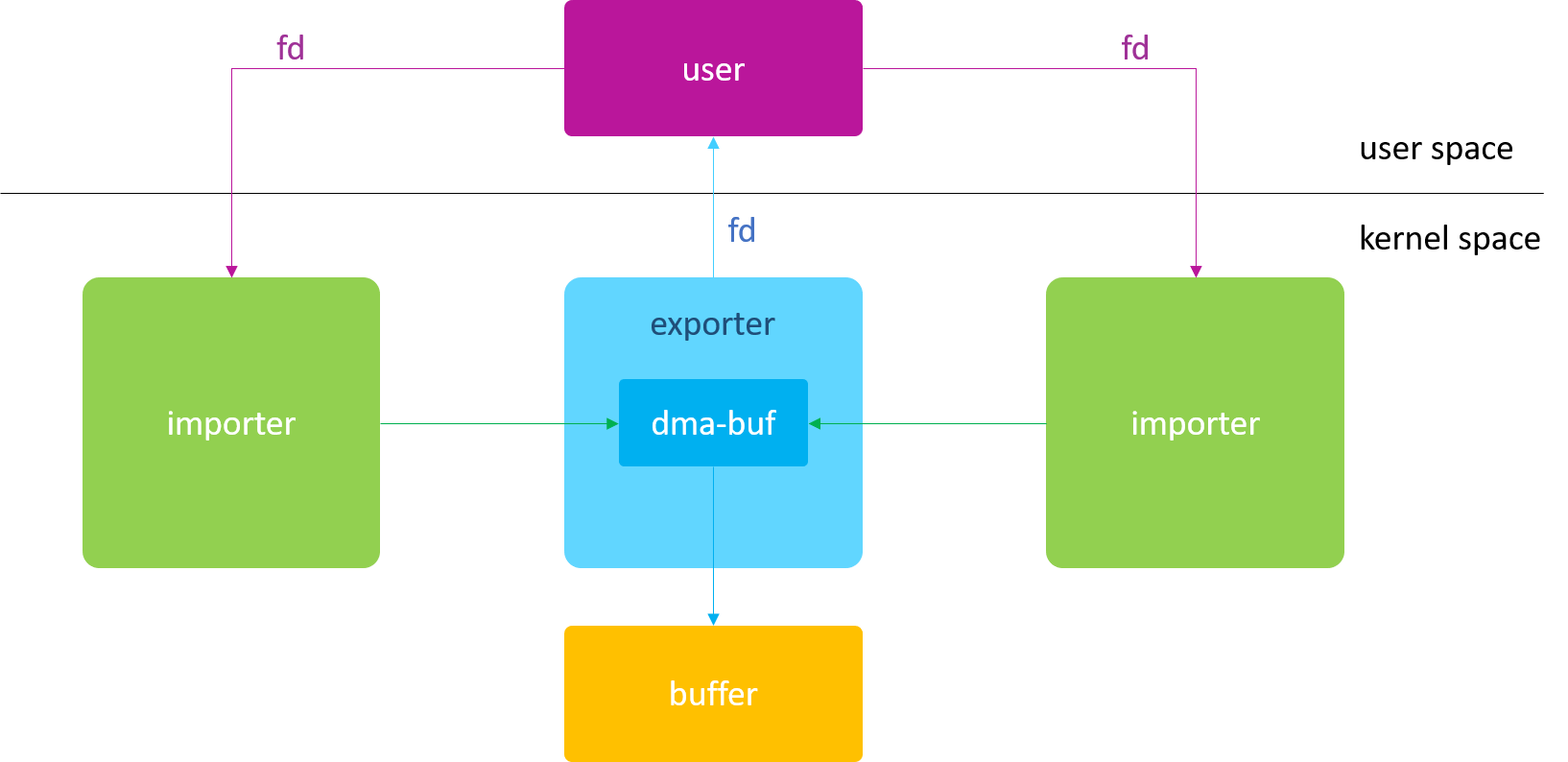
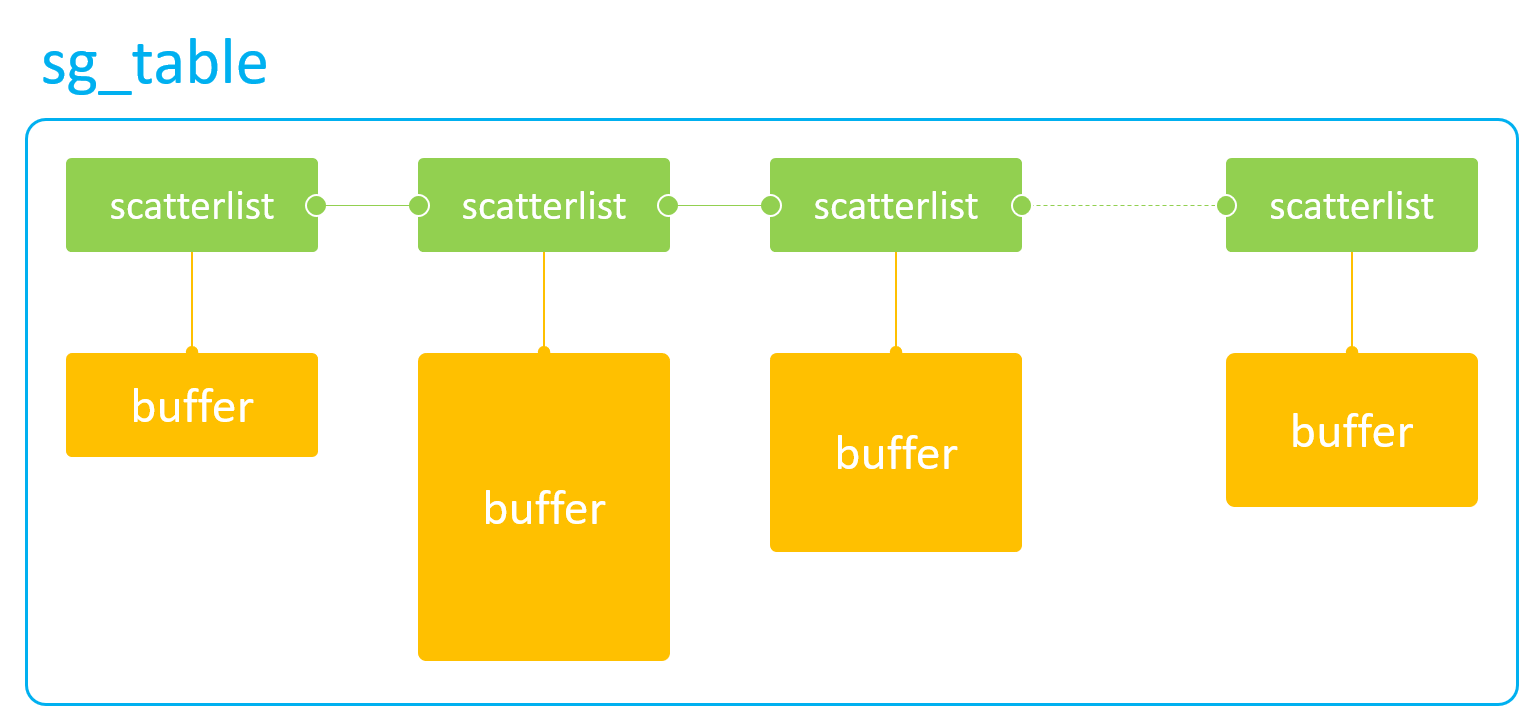
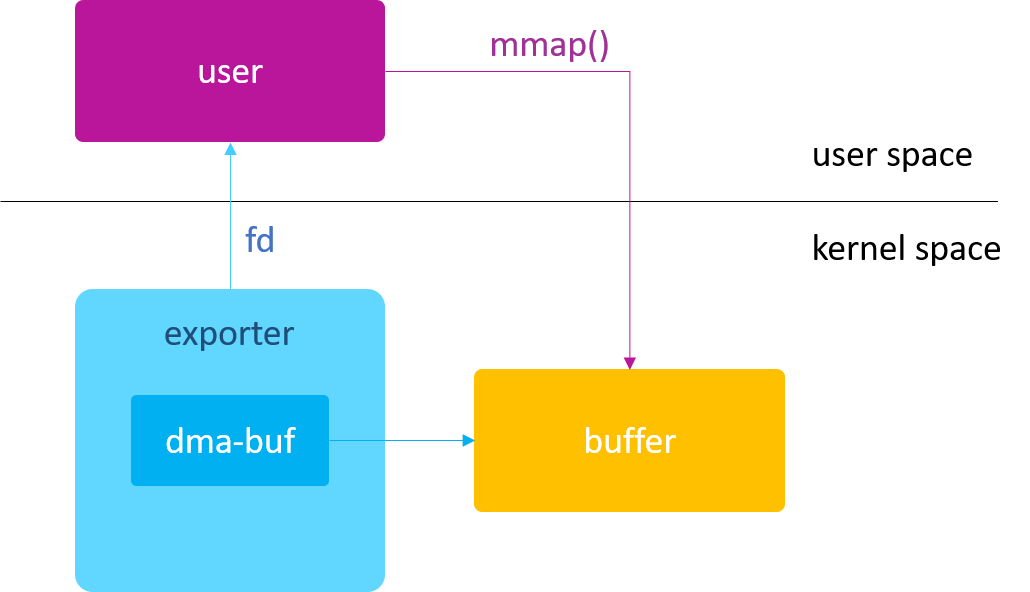
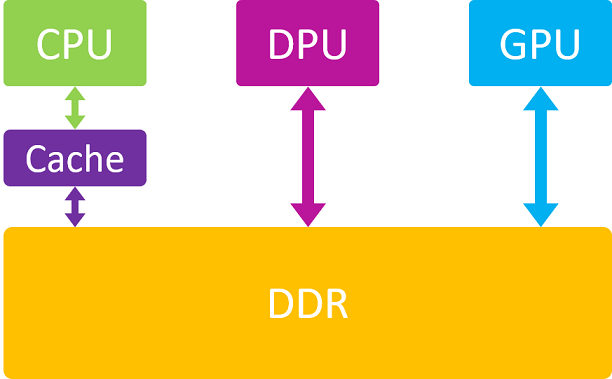
如果硬件 A 和 B 的寻址空间有交集,则在 export 阶段进行内存分配,分配时以 A / B 的交集为准;
如果硬件 A 和 B 的寻址空间没有交集,则只能在 map attachment 阶段分配内存。
对于第二种策略,因为 A 和 B 的寻址空间没有交集(即完全独立),所以它们实际上是无法实现内存共享的。 此时的解决办法是: A 和 B 在 map attachment 阶段,都分配各自的物理内存,然后通过 CPU 或 通用DMA 硬件, 将 A 的 buffer 内容拷贝到 B 的 buffer 中去,以此来间接的实现 buffer “共享”。
/** * container_of - cast a member of a structure out to the containing structure * @ptr: the pointer to the member. * @type: the type of the container struct this is embedded in. * @member: the name of the member within the struct. * */ #define container_of(ptr, type, member) ({ \ const typeof(((type *)0)->member) * __mptr = (ptr); \ (type *)((char *)__mptr - offsetof(type, member)); })
/** * list_for_each_entry - iterate over list of given type * @pos: the type * to use as a loop cursor. * @head: the head for your list. * @member: the name of the list_head within the struct. */ #define list_for_each_entry(pos, head, member) \ for (pos = list_first_entry(head, typeof(*pos), member); \ !list_entry_is_head(pos, head, member); \ pos = list_next_entry(pos, member))
/** * list_for_each_entry_safe - iterate over list of given type safe against removal of list entry * @pos: the type * to use as a loop cursor. * @n: another type * to use as temporary storage * @head: the head for your list. * @member: the name of the list_head within the struct. */ #define list_for_each_entry_safe(pos, n, head, member) \ for (pos = list_first_entry(head, typeof(*pos), member), \ n = list_next_entry(pos, member); \ !list_entry_is_head(pos, head, member); \ pos = n, n = list_next_entry(n, member))
The Git cloning of repository succeeds on a Linux client but fails on a Windows client with an “invalid path” error.
Solution
Depending on the filename, configuring Git to ignore NTFS naming may workaround the issue.
1
git config --global core.protectNTFS false
Turning off protectNTFS will stop Git from complaining about files that have a base name that is reserved but will not prevent an error if the filename is one of the reserved names.