Dma_buf
dma-buf
dma-buf的出现是为了解决各驱动之间buffer共享的问题,因此它本质上是buffer和file的结合,即它既是一块物理连续的buffer,
也是一个linux file。buffer是内容,file是媒介,通过file这个媒介来实现buffer的共享。
一个典型的dma-buf的应用框架如下: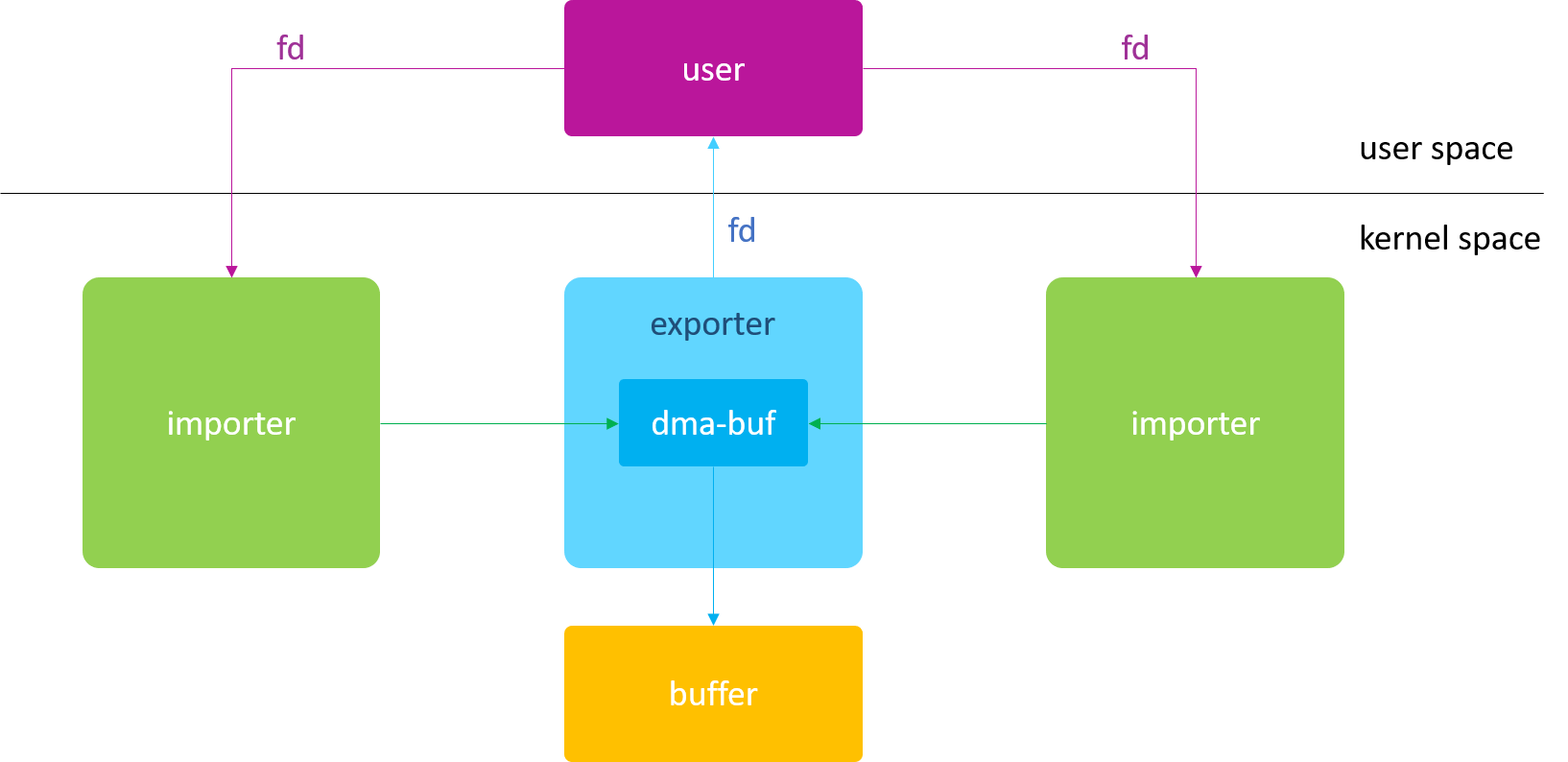
通常,分配buffer的模块称为exportor,使用该buffer的模块称为importor或user。
一个最简单的dma-buf驱动包含以下元素:
- dma_buf_ops
- DEFINE_DMA_BUF_EXPORT_INFO
- dma_buf_export()
dma-buf 不仅仅只能用于DMA硬件访问
dma-buf本质是buffer和file的结合,任然是一块buffer,不仅能用于DMA硬件访问,也同样适应CPU软件访问,这也是dma-buf在内核中
广受欢迎的一个重要原因。经过他的API都带有dma字样。
dma-buf既能分配物理连续的buffer,也可以是离散的buffer
分配那种beffer最终取决与exportor驱动采用何种方式来分配buffer。例如:采用内核中最常见的kmalloc()函数来分配dma-buf,这块buffer
自然就是物理连续的。
CPU Access
从 linux-3.4 开始,dma-buf 引入了 CPU 操作接口,使得开发人员可以在内核空间里直接使用 CPU 来访问 dma-buf 的物理内存。
如下 dma-buf API 实现了 CPU 在内核空间对 dma-buf 内存的访问:
- dma_buf_kmap()
- dma_buf_kmap_atomic()
- dma_buf_vmap()
(它们的反向操作分别对应各自的 unmap 接口)
通过 dma_buf_kmap() / dma_buf_vmap() 操作,就可以把实际的物理内存,映射到 kernel 空间,并转化成 CPU 可以连续访问的虚拟地址
方便后续软件直接读写这块物理内存。因此,无论这块 buffer 在物理上是否连续,在经过 kmap / vmap 映射后的虚拟地址一定是连续的。
上述的3个接口分别和 linux 内存管理子系统(MM)中的 kmap()、 kmap_atomic() 和 vmap() 函数一一对应,三者的区别如下:
|函数| 说明|
|–|–|
|kmap()| 一次只能映射1个page,可能会睡眠,只能在进程上下文中调用|
|kmap_atomic()| 一次只能映射1个page,不会睡眠,可在中断上下文中调用|
|vmap()| 一次可以映射多个pages,且这些pages物理上可以不连续,只能在进程上下文中调用|
从 linux-4.19 开始,dma_buf_kmap_atomic() 不再被支持。
dma_buf_ops 中的 map / map_atomic 接口名,其实原本就叫 kmap / kmap_atomic,只是后来发现与 highmem.h 中的宏定义重名了,
了避免开发人员在自己的驱动中引用 highmem.h 而带来的命名冲突问题,于是去掉了前面的“k”字。
DMA Access
dma-buf 允许CPU 在 kernel 空间访问 dma-buf 物理内存,但通常这种操作方法在内核中出现的频率并不高,因为 dma-buf 设计之初
就是为满足那些大内存访问需求的硬件而设计的,如GPU/DPU。在这种场景下,如果使用CPU直接去访问 memory,那么性能会大大降低。
因此,dma-buf 在内核中出现频率最高的还是
- dma_buf_attach()
- dma_buf_map_attachment()
这两个接口是dma-buf提供给DMA硬件访问的主要API,而且两者有严格的调用顺序,必须先attach,再map_attachment,因为后者的参数
是由前者提供的,所以通常这两个接口形影不离。
两个 API 相对应的反向操作接口为: dma_buf_dettach() 和 dma_buf_unmap_attachment()
sg_table
sg_table 是 dma-buf 供 DMA 硬件访问的终极目标,也是 DMA 硬件访问离散 memory 的唯一途径。
sg_table 本质上是由一块块单个物理连续的 buffer 所组成的链表,但是这个链表整体上看却是离散的,
因此它可以很好的描述从高端内存上分配出的离散 buffer。当然,它同样可以用来描述从低端内存上分配出的物理连续 buffer。
如下图所示: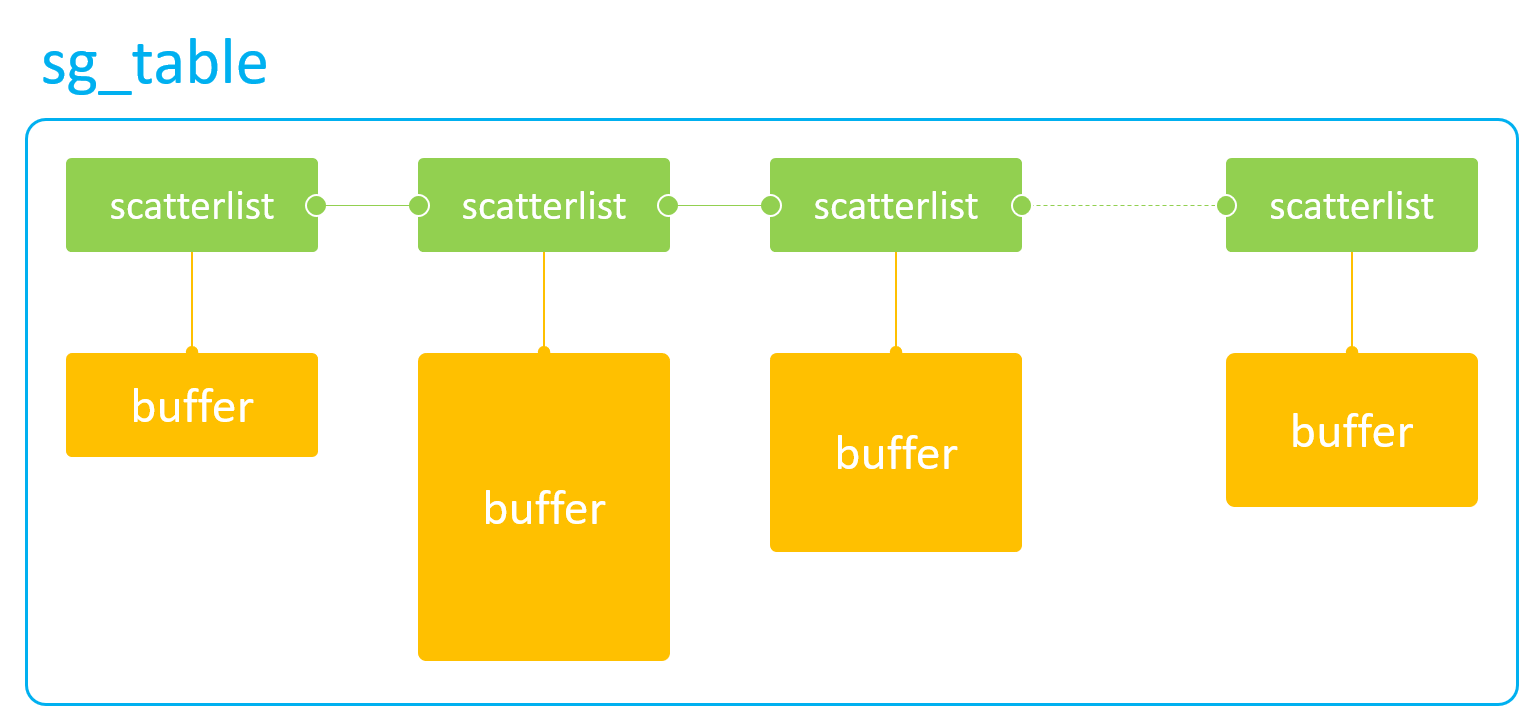
sg_table代表着整个链表,而它的每一个链表项则由scatterlist来表示。因此,1个scatterlist也就对应着一块物理连续的 buffer。
通过如下接口来获取一个scatterlist对应 buffer 的物理地址和长度:
- sg_dma_address(sgl)
- sg_dma_len(sgl)
有了 buffer 的物理地址和长度,可以将这两个参数配置到 DMA 硬件寄存器中,这样就可以实现 DMA 硬件对这一小块 buffer 的访问。
如果需要访问整块离散 buffer ,可通过使用 for 循环,不断的解析scatterlist,不断的配置 DMA 硬件寄存器。
对于现代多媒体硬件来说,IOMMU 的出现,解决了程序员编写 for 循环的烦恼。因为在 for 循环中,每次配置完 DMA 硬件寄存器后,
都需要等待本次 DMA 传输完毕,然后才能进行下一次循环,这大大降低了软件的执行效率。而 IOMMU 的功能就是用来解析 sg_table 的,
它会将 sg_table 内部一个个离散的小 buffer 映射到自己内部的设备地址空间,使得这整块 buffer 在自己内部的设备地址空间上是连续的
这样,在访问离散 buffer 的时候,只需要将 IOMMU 映射后的设备地址(与 MMU 映射后的 CPU 虚拟地址不是同一概念)和整块 buffer 的
size 配置到 DMA 硬件寄存器中即可,中途无需再多次配置,便完成了 DMA 硬件对整块离散 buffer 的访问,大大的提高了软件的效率。
dma_buf_attach()
该函数实际上是dma-buf attach device的缩写,用于建立一个device与dma-buf的链接关系,这个连接关系被存放在新创建的dma_buf_attachment对象中,供后续调用dma_buf_map_attachment()使用。
该函数对应dma_buf_ops中的回调接口,如果device对后续的map_attachment操作没有特殊要求,可以不实现。
dma_buf_map_attachment()
该函数实际上是dma-buf map attachment into sg_table的缩写,主要完成2件事:
- 生成 sg_table
- 同步 Cache
选择返回sg_table而不是物理地址,是为了兼容所有DMA硬件(带或不带IOMMU),因为sg_table既可以表示连续物理内存,也可以表示
非连续物理内存。
同步Cache是为了防止该buffer事先被CPU填充过,数据暂存在Cache中而非DDR上,导致DMA访问的不是最新的有效数据。
通过刷cache避免此类问题。同样的,在DMA访问内存结束后,需要将Cache设置为无效(no-Cache),以便后续CPU直接从DDR上读取数据。
通常使用如下流式DMA映射接口来完成Cache的同步:
- dma_map_single() / dma_unmap_single()
- dma_map_page() / dma_unmap_page()
- dma_map_sg() / dma_unmap_sg()
dma_buf_map_attachment() 对应 dma_buf_ops 中的 map_dma_buf 回调接口,
该回调接口(包括 unmap_dma_buf 在内)被强制要求实现。
延伸:
dma_buf_ops中部分回调被要求强制实现。
为什么要attach操作
同一个 dma-buf 可能会被多个 DMA 硬件访问,而每个 DMA 硬件可能会因为自身硬件能力的限制,对这块 buffer 有自己特殊的要求。
比如硬件 A 的寻址能力只有0x0 ~ 0x10000000,而硬件 B 的寻址能力为 0x0 ~ 0x80000000,那么在分配 dma-buf 的物理内存时,
就必须以硬件 A 的能力为标准进行分配,这样硬件 A 和 B 都可以访问这段内存。
否则,如果只满足 B 的需求,那么 A 可能就无法访问超出 0x10000000 地址以外的内存空间,道理其实类似于木桶理论。
因此,attach 操作可以让 exporter 驱动根据不同的 device 硬件能力,来分配最合适的物理内存。
通过设置 device->dma_params 参数,来告知 exporter 驱动该 DMA 硬件的能力限制。
何时分配内存
既可以在 export 阶段分配,也可以在 map_attachment 阶段分配,甚至可以在两个阶段都分配,这通常由 DMA 硬件能力来决定。
首先,驱动人员需要统计当前系统中都有哪些 DMA 硬件要访问 dma-buf;
然后,根据不同的 DMA 硬件能力,来决定在何时以及如何分配物理内存。
通常的策略如下(假设只有 A、B 两个硬件需要访问 dma-buf ):
- 如果硬件 A 和 B 的寻址空间有交集,则在 export 阶段进行内存分配,分配时以 A / B 的交集为准;
- 如果硬件 A 和 B 的寻址空间没有交集,则只能在 map attachment 阶段分配内存。
对于第二种策略,因为 A 和 B 的寻址空间没有交集(即完全独立),所以它们实际上是无法实现内存共享的。
此时的解决办法是: A 和 B 在 map attachment 阶段,都分配各自的物理内存,然后通过 CPU 或 通用DMA 硬件,
将 A 的 buffer 内容拷贝到 B 的 buffer 中去,以此来间接的实现 buffer “共享”。
另外还有一种策略,就是不管三七二十一,先在 export 阶段分配好内存,然后在首次 map attachment 阶段
通过 dma_buf->attachments 链表,与所有 device 的能力进行一一比对,如果满足条件则直接返回 sg_table;
如果不满足条件,则重新分配符合所有 device 要求的物理内存,再返回新的 sg_table。
总结
- sg_table 是 DMA 硬件操作的关键;
- attach 的目的是为了让后续 map attachment 操作更灵活;
- map attachment 主要完成两件事:生成 sg_table 和 Cache 同步;
- DMA 的硬件能力决定了 dma-buf 物理内存的分配时机;
在user space 访问 dma-buf
user space 访问 dma-buf 也属于 CPU Access 的一种。
mmap
为了方便应用程序能直接在用户空间读写 dma-buf 的内存,dma_buf_ops为我们提供了一个mmap回调接口,
可以把 dma-buf 的物理内存直接映射到用户空间,这样应用程序就可以像访问普通文件那样访问 dma-buf 的物理内存了。
在 Linux 设备驱动中,大多数驱动的 mmap 操作接口都是通过调用
remap_pfn_range()函数来实现的,dma-buf 也不例外
除了dma_buf_ops提供的 mmap 回调接口外,dma-buf 还为我们提供了dma_buf_mmap()内核 API,
使得我们可以在其他设备驱动中就地取材,直接引用 dma-buf 的 mmap 实现,以此来间接的实现设备驱动的 mmap 文件操作接口
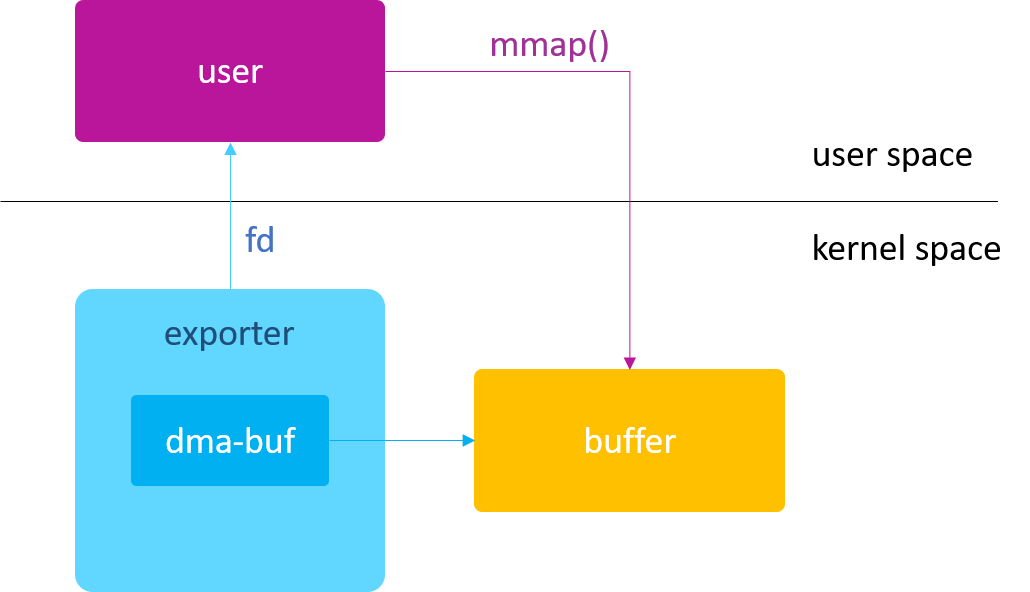
file
dma-buf 本质上是 buffer 与 file 的结合,既然与file有关系,就涉及到fd
fd
如下内核 API 实现了 dma-buf 与 fd 之间的相互转换:
- dma_buf_fd():dma-buf –> new fd
- dma_buf_get():fd –> dma-buf
通常使用方法如下:
1 | fd = dma_buf_fd(dmabuf); |
get / put
只要是文件,内部都会有一个引用计数(f_count)。当dma_buf_export()函数创建dma-buf时,该引用计数被初始化为1;当这个引用计数为0时,则会自动触发dma_buf_ops的release回调接口,并释放dma-buf对象。
linux内核中操作file引用计数的常用函数为fget()和fput(),而dma-buf又在此基础上进行了封装,如下:
- get_dma_buf()
- dma_buf_get()
- dma_buf_put()
其中区别如下:
| 函数 | 区别 |
|---|---|
| get_dma_buf() | 仅引用计数加1 |
| dma_buf_get() | 引用计数加1,并将 fd 转换成 dma_buf 指针 |
| dma_buf_put() | 引用计数减1 |
| dma_buf_fd() | 引用计数不变,仅创建 fd |
release
通常 release 回调接口用来释放 dma-buf 所对应的物理 buffer。
凡是所有和该 dma-buf 相关的私有数据也都应该在这里被 free 掉。
前面说过,只有当 dma-buf 的引用计数递减到0时,才会触发 release 回调接口。因此
- 如果不想正在使用的 buffer 被突然释放,请提前 get;
- 如果想在 kernel space 释放 buffer,请使劲 put;
- 如果想从 user space 释放 buffer,请尝试 close;
这就是为什么在内核设备驱动中,我们会看到那么多 dma-buf get 和 put 的身影
如果没有任何程序来修改该 dma-buf 的引用计数,自始自终都保持为1,会无法执行 release 接口
这会导致 buffer 无法被释放,造成内存泄漏
跨进程 fd
做 Linux 应用开发的同事都知道,fd 属于进程资源,它的作用域只在单个进程空间范围内有效,即同样的 fd 值,
在进程 A 和 进程 B 中所指向的文件是不同的。因此 fd 是不能在多个进程之间共享的,
也就是说 dma_buf_fd() 与 dma_buf_get() 只能是在同一进程中调用。
fd 并不是完全不能在多进程中共享,而是需要采用特殊的方式进行传递。
在 linux 系统中,最常用的做法就是通过 socket 来实现 fd 的传递。而在 Android 系统中,则是通过 Binder 来实现的。
需要注意的是,传递后 fd 的值可能会发生变化,但是它们所指向的文件都是同一文件。
总之,有了 Binder,dma_buf_fd() 和 dma_buf_get() 就可以不用严格限制在同一进程中使用了。
总结
为什么需要fd?
方便应用程序直接在 user space 访问该 buffer,通过 mmap;
方便该 buffer 在各个驱动模块之间流转,而无需拷贝;
降低了各驱动之间的耦合度。
如何实现 fd 跨进程共享? Binder!
get / put 将影响 dma-buf 的内存释放
Cache 一致性
dma-buf 有以下接口用于 Cache 同步:
- begin_cpu_access
- end_cpu_access
CPU 与 DMA 访问 DDR 之间的区别: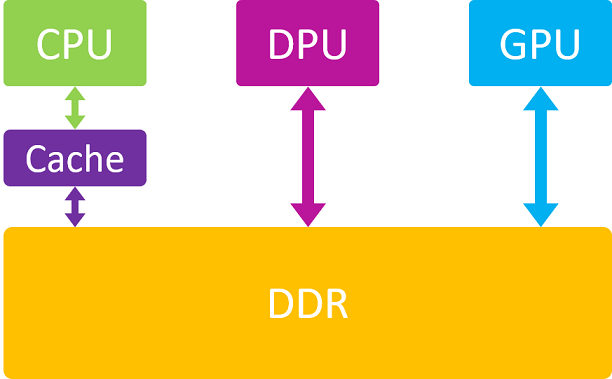
CPU 在访问内存时是要经过 Cache 的,而 DMA 外设则是直接和 DDR 打交道,因此这就存在 Cache 一致性的问题了
即 Cache 里面的数据是否和 DDR 里面的数据保持一致。
比如 DMA 外设早已将 DDR 中的数据改写了,而 CPU 却浑然不知,仍然在访问 Cache 里面暂存的旧数据。
所以 Cache 一致性问题,只有在 CPU 参与访问的情况下才会发生。
如果一个 dma-buf 自始自终都只被一个硬件访问(要么CPU,要么DMA),那么 Cache 一致性问题就不会存在。
当然,如果一个 dma-buf 所对应的物理内存本身就是 Uncache 的(也叫一致性内存),
或者说该 buffer 在被分配时是以 coherent 方式分配的,
这种情况下,CPU 是不经过 cache 而直接访问 DDR 的,自然 Cache 一致性问题也就不存在了。
为什么需要 begin / end 操作?
dma-buf使用流式 DMA 映射接口来实现 Cache 同步操作。这类接口的特点就是 Cache 同步只是一次性的,
即在 dma map 的时候执行一次 Cache Flush 操作,在 dma unmap 的时候执行一次 Cache Invalidate 操作,
而这中间的过程是不保证 Cache 和 DDR 上数据的一致性的。
因此如果 CPU 在 dma map 和 unmap 之间又去访问了这块内存,
那么有可能 CPU 访问到的数据就只是暂存在 Cache 中的旧数据,这就带来了问题。
那么什么情况下会出现 CPU 在 dma map 和 unmap 期间又去访问这块内存呢?
一般不会出现 DMA 硬件正在传输过程中突然 CPU 发起访问的情况,
而更多的是在 DMA 硬件发起传输之前,或 DMA 硬件传输完成之后,
并且仍然处于 dma map 和 unmap 操作之间的时候,CPU 对这段内存发起了访问。
针对这种情况,就需要在 CPU 访问内存前,先将 DDR 数据同步到 Cache 中(Invalidate);
在 CPU 访问结束后,将 Cache 中的数据回写到 DDR 上(Flush),以便 DMA 能获取到 CPU 更新后的数据。
这也就是 dma-buf 给我们预留 {begin,end}_cpu_access 的原因。
Kernel API
dma-buf 为我们提供了如下内核 API,用来在 dma map 期间发起 CPU 访问操作:
- dma_buf_begin_cpu_access()
- dma_buf_end_cpu_access()
它们分别对应 dma_buf_ops 中的 begin_cpu_access 和 end_cpu_access 回调接口。
通常在驱动设计时, begin_cpu_access / end_cpu_access 使用如下流式 DMA 接口来实现 Cache 同步:
- dma_sync_single_for_cpu() / dma_sync_single_for_device()
- dma_sync_sg_for_cpu() / dma_sync_sg_for_device()
CPU 访问内存之前,通过调用 dma_sync_{single,sg}_for_cpu() 来 Invalidate Cache,
这样 CPU 在后续访问时才能重新从 DDR 上加载最新的数据到 Cache 上。
CPU 访问内存结束之后,通过调用 dma_sync_{single,sg}_for_device() 来 Flush Cache,将 Cache 中的数据全部回写到 DDR 上,
这样后续 DMA 才能访问到正确的有效数据。
User API
考虑到 mmap() 操作,dma-buf 也为我们提供了 Userspace 的同步接口,通过 DMA_BUF_IOCTL_SYNC ioctl() 来实现。
该 cmd 需要一个 struct dma_buf_sync 参数,用于表明当前是 begin 还是 end 操作,是 read 还是 write 操作。
总结
- 只有在 DMA map/unmap 期间 CPU 又要访问内存的时候,才有必要使用 begin / end 操作;
- { begin,end }_cpu_access 实际是 dma_sync()* 接口的封装,目的是要 invalidate 或 flush cache;
- Usespace 通过 DMA_BUF_IOCTL_SYNC 来触发 begin / end 操作;